
Visualizing Attention Maps in Pre-trained Vision Transformers (Pytorch)
Goal: Visualizing the attention maps for the CLS token in a pretrained Vision Transformer from the timm library.
For a better experience, open in Colab: ![]()
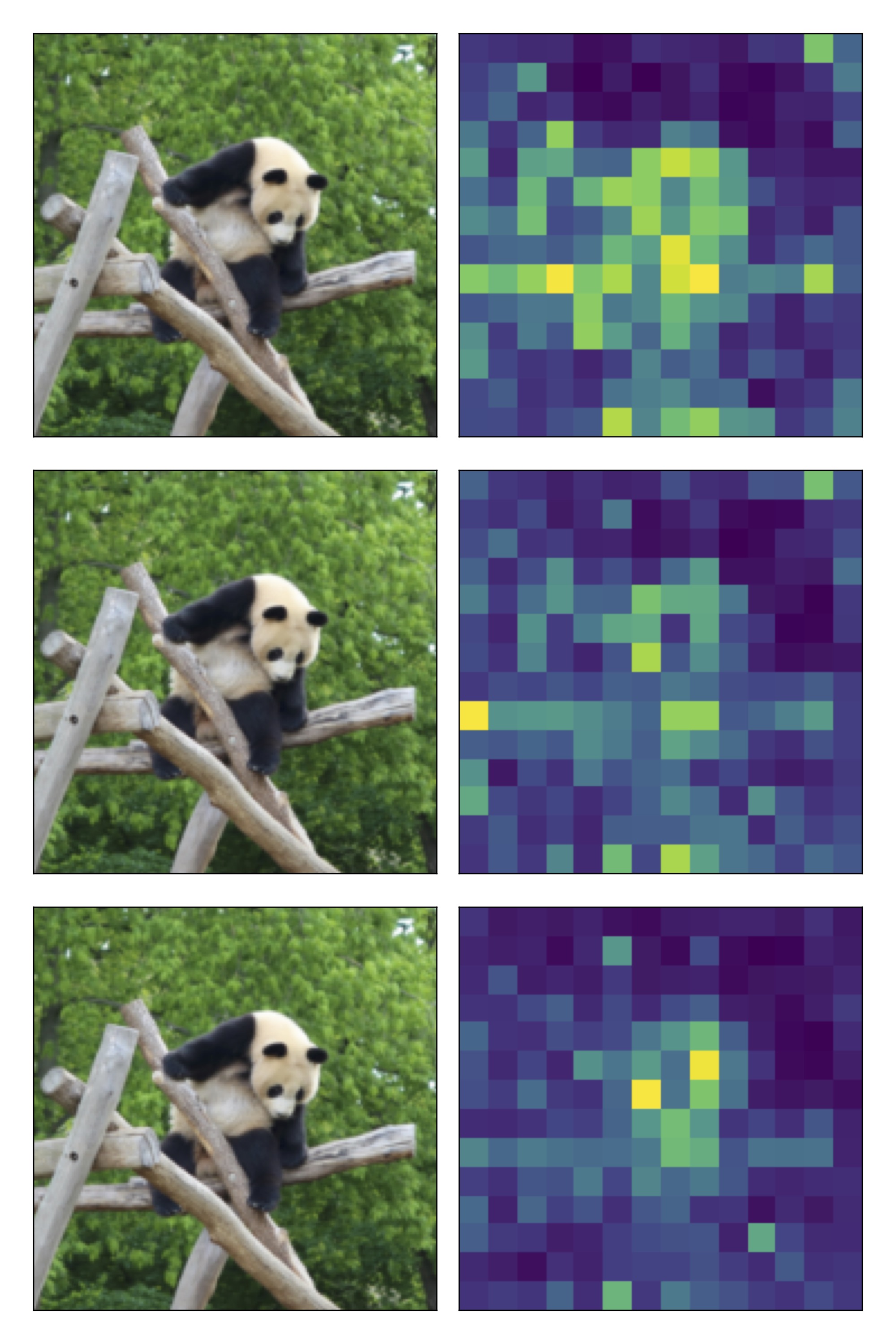
In this short notebook, we’ll try to get some insights into pre-trained vision transformers by looking at attention patterns. More specifically, we’ll plot the attention scores between the CLS token and other tokens and check whether they have a semantic interpretation or not. This is often the case, so we expect to images like this:
# install timm
!pip install timm
We load a pre-trained DeiT (data efficient Vision Transformer) see he here.
Anyway, Timm has
plenty of
pre-trained models to choose from.
import torch
model = torch.hub.load('facebookresearch/deit:main', 'deit_tiny_patch16_224', pretrained=True)
print(model)
VisionTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 192, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)
(pos_drop): Dropout(p=0.0, inplace=False)
(patch_drop): Identity()
(norm_pre): Identity()
(blocks): Sequential(
(12x): Block(
(norm1): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=192, out_features=576, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=192, out_features=192, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=192, out_features=768, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=768, out_features=192, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
))
...
The original code can be found here. We can see the attention scores are not returned (unlike the Pytorch implementation) so we have to "feature extract" them.
More specifically, we see that in the attention class the attention score are computed as
attn = self.attn_drop(attn)
and only when sdpa attention is not enabled. Before going on, let's
disable the sdpa attention in each block.
for block in model.blocks:
block.attn.fused_attn = False
Now we are ready to extract the features. We'll do it with a very cool
torch feature extraction tool called torch.fx. This allows you to
extract all intermediate activations from a model without the cumbersome
process of adding hooks or subclassing the forward, you can find more
info
here.
Let's see which features we can extract, using get_graph_node_names.
from torchvision.models.feature_extraction import get_graph_node_names
nodes, _ = get_graph_node_names(model)
print(nodes)
['x', 'patch_embed.getattr', 'patch_embed.getitem', 'patch_embed.getitem_1', 'patch_embed.getitem_2', 'patch_embed.getitem_3', 'patch_embed.eq', 'patch_embed._assert', 'patch_embed.eq_1', 'patch_embed._assert_1', 'patch_embed.proj', 'patch_embed.flatten', 'patch_embed.transpose', 'patch_embed.norm', 'pos_embed', 'cls_token', 'getattr', 'getitem', 'expand', 'cat', 'add', 'pos_drop', 'patch_drop', 'norm_pre', 'blocks.0.norm1', 'blocks.0.attn.getattr', 'blocks.0.attn.getitem', 'blocks.0.attn.getitem_1', 'blocks.0.attn.getitem_2', 'blocks.0.attn.qkv', 'blocks.0.attn.reshape', 'blocks.0.attn.permute', 'blocks.0.attn.unbind', 'blocks.0.attn.getitem_3', 'blocks.0.attn.getitem_4', 'blocks.0.attn.getitem_5', 'blocks.0.attn.q_norm', 'blocks.0.attn.k_norm', 'blocks.0.attn.mul', 'blocks.0.attn.transpose', 'blocks.0.attn.matmul', 'blocks.0.attn.softmax', 'blocks.0.attn.attn_drop', 'blocks.0.attn.matmul_1', 'blocks.0.attn.transpose_1', 'blocks.0.attn.reshape_1', 'blocks.0.attn.proj', 'blocks.0.attn.proj_drop', 'blocks.0.ls1', 'blocks.0.drop_path1', 'blocks.0.add', 'blocks.0.norm2', 'blocks.0.mlp.fc1', 'blocks.0.mlp.act', 'blocks.0.mlp.drop1', 'blocks.0.mlp.norm', 'blocks.0.mlp.fc2', 'blocks.0.mlp.drop2', 'blocks.0.ls2', 'blocks.0.drop_path2', 'blocks.0.add_1', 'blocks.1.norm1', 'blocks.1.attn.getattr', 'blocks.1.attn.getitem', 'blocks.1.attn.getitem_1', 'blocks.1.attn.getitem_2', 'blocks.1.attn.qkv', 'blocks.1.attn.reshape', 'blocks.1.attn.permute', 'blocks.1.attn.unbind', 'blocks.1.attn.getitem_3', 'blocks.1.attn.getitem_4', 'blocks.1.attn.getitem_5', 'blocks.1.attn.q_norm', 'blocks.1.attn.k_norm', 'blocks.1.attn.mul', 'blocks.1.attn.transpose', 'blocks.1.attn.matmul', 'blocks.1.attn.softmax', 'blocks.1.attn.attn_drop', 'blocks.1.attn.matmul_1', 'blocks.1.attn.transpose_1', 'blocks.1.attn.reshape_1', 'blocks.1.attn.proj', 'blocks.1.attn.proj_drop', 'blocks.1.ls1', 'blocks.1.drop_path1', 'blocks.1.add', 'blocks.1.norm2', 'blocks.1.mlp.fc1', 'blocks.1.mlp.act', 'blocks.1.mlp.drop1', 'blocks.1.mlp.norm', 'blocks.1.mlp.fc2', 'blocks.1.mlp.drop2', 'blocks.1.ls2', 'blocks.1.drop_path2', 'blocks.1.add_1', 'blocks.2.norm1', ...]
# A lot of useless stuff
# we only care for nodes that contain attn_drop
interesting_nodes = [x for x in nodes if 'attn_drop' in x]
print(interesting_nodes)
['blocks.0.attn.attn_drop', 'blocks.1.attn.attn_drop', 'blocks.2.attn.attn_drop', 'blocks.3.attn.attn_drop', 'blocks.4.attn.attn_drop', 'blocks.5.attn.attn_drop', 'blocks.6.attn.attn_drop', 'blocks.7.attn.attn_drop', 'blocks.8.attn.attn_drop', 'blocks.9.attn.attn_drop', 'blocks.10.attn.attn_drop', 'blocks.11.attn.attn_drop']
Makes sense, we have one attention for each layer.
Before going on, some standard stuff to normalize and denormalize the image for plotting.
!wget https://raw.githubusercontent.com/alessiodevoto/notebooks/refs/heads/main/data/bird.jpg
Some image processing basic stuff.
# Load and preprocess image
from PIL import Image
from torchvision import transforms
mean, std = [0.485, 0.456, 0.406], [0.229, 0.224, 0.225]
img = Image.open('bird.jpg')
preprocess = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std),
])
def denormalize(image):
denormalized_image = image * torch.tensor(std).view(3, 1, 1) + torch.tensor(mean).view(3, 1, 1)
return denormalized_image
img_tensor = preprocess(img).unsqueeze(0)
We finally extract the attention scores. We see we are interested in all
those nodes that contain attn_drop.
from torchvision.models.feature_extraction import create_feature_extractor
feature_extractor = create_feature_extractor(
model, return_nodes=interesting_nodes)
# `out` will be a dict of Tensors, each representing a feature map
out = feature_extractor(img_tensor)
for k, v in out.items():
print(k, v.shape)
We see the attention scores have shape
(batch, num_heads, num_patches+1, num_patches+1), where the +1 is
because we added the CLS token.
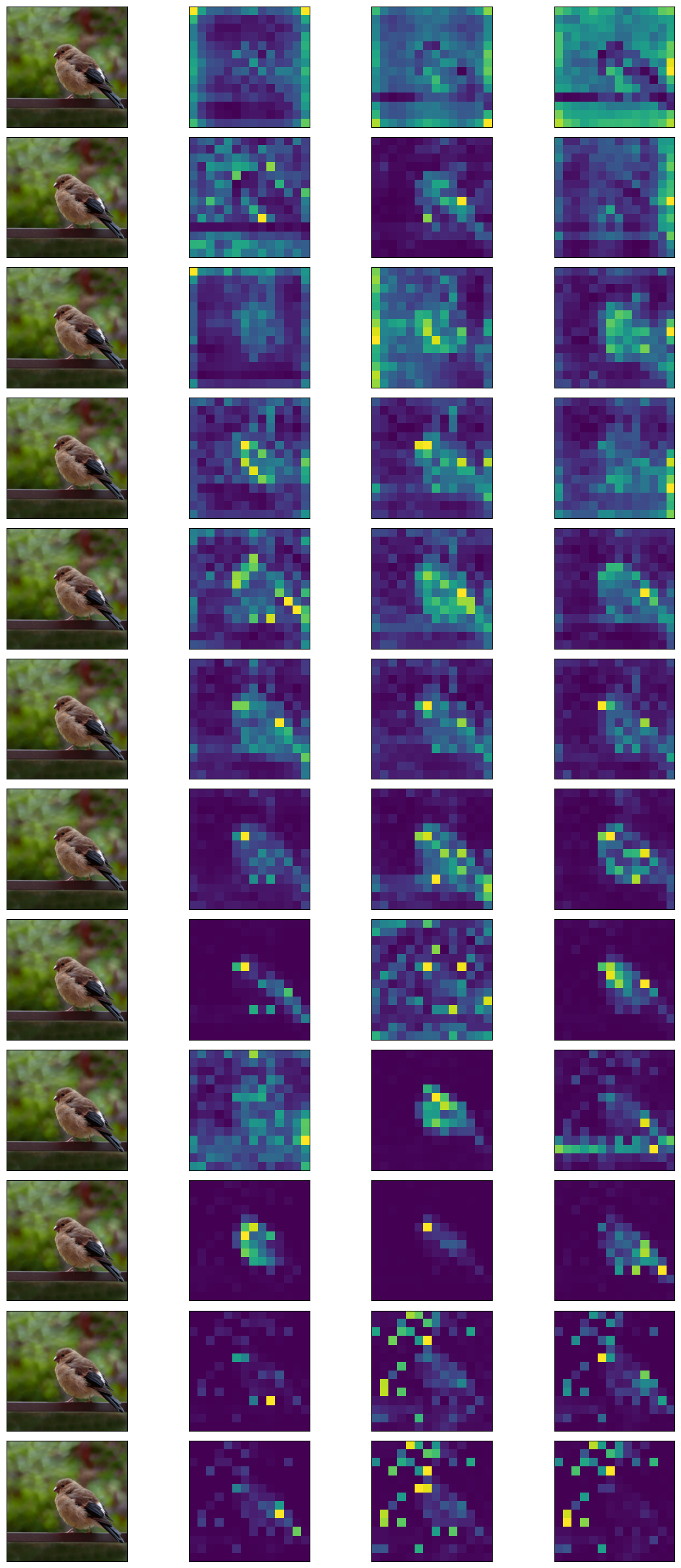
Let's iterate over the attention scores and plot them for each head.
import matplotlib.pyplot as plt
import numpy as np
num_layers = 12
num_heads = 3
# create subplots of 12 x 4
fig, axs = plt.subplots(num_layers, num_heads+1, figsize=(12, 24))
for i, (k, v) in enumerate(out.items()):
# class token attention scores
attn_scores = v.squeeze() #remove the batch dimension
# print(attn_scores.shape)
for head in range(num_heads):
attn_scores_head = attn_scores[head]
# print(attn_scores_head.shape)
cls_token_attn_scores = attn_scores_head[0,1:]
# print(cls_token_attn_scores.shape)
axs[i,head+1].imshow(cls_token_attn_scores.reshape(14,14).detach(), cmap='viridis')
axs[i,0].imshow(denormalize(img_tensor).detach().numpy().squeeze().transpose(1,2,0))
# hide ticks
for ax in axs.flat:
ax.set(xticks=[], yticks=[])
plt.tight_layout()
Hope you liked this! If you have any suggestions/questios, feel free to drop me a message/email or visit my page or my twitter @devoto_alessio.